为了快速发现线上 Node.js 服务问题,需要利用告警系统,来快速发现、通知开发者,从而快速回滚/修复问题。
认识告警中台
在开始前,需要认识一下告警中台。云开发Nodejs的告警系统,就是基于告警中台开发的。
自定义字段
能自定义告警字段,这些字段来自:告警任务设计中的任务触发告警时,传给中台 API 的参数。
这些字段可以被用来下发通知时,替换消息模板中的变量字段。
告警升级
当正式下发的告警没有被「认领」,那么就会触发告警升级。
通过手机或者短信等形式,来触达接受者。
告警屏蔽
告警触发后,在修复完成前,可能会重复触发。
此时,屏蔽告警,进行处理即可。
告警订阅
向指定用户、群组配置告警触发的途径。
告警回调
当告警触发后,向回调地址发送请求。
可以用来自定义统计告警信息。
告警收敛
收敛时长:指定时间内,相同告警收敛为 1 条。
收敛的作用:防止同一时间大量相同告警,淹没其他少量但是重要的告警。
收敛升级:当指定时间内的相同告警超过指定数目,立即升级告警。
收敛升级的作用:收敛后,总数量无法展示,无法体现紧急程度。当数量过多,说明是重大问题,应该进行升级。
告警恢复
指定时间内,没有相同告警,则发送恢复消息。
有些告警是网络抖动的原因,或者其他偶发性因素,不具备常态。
告警系统
整体架构
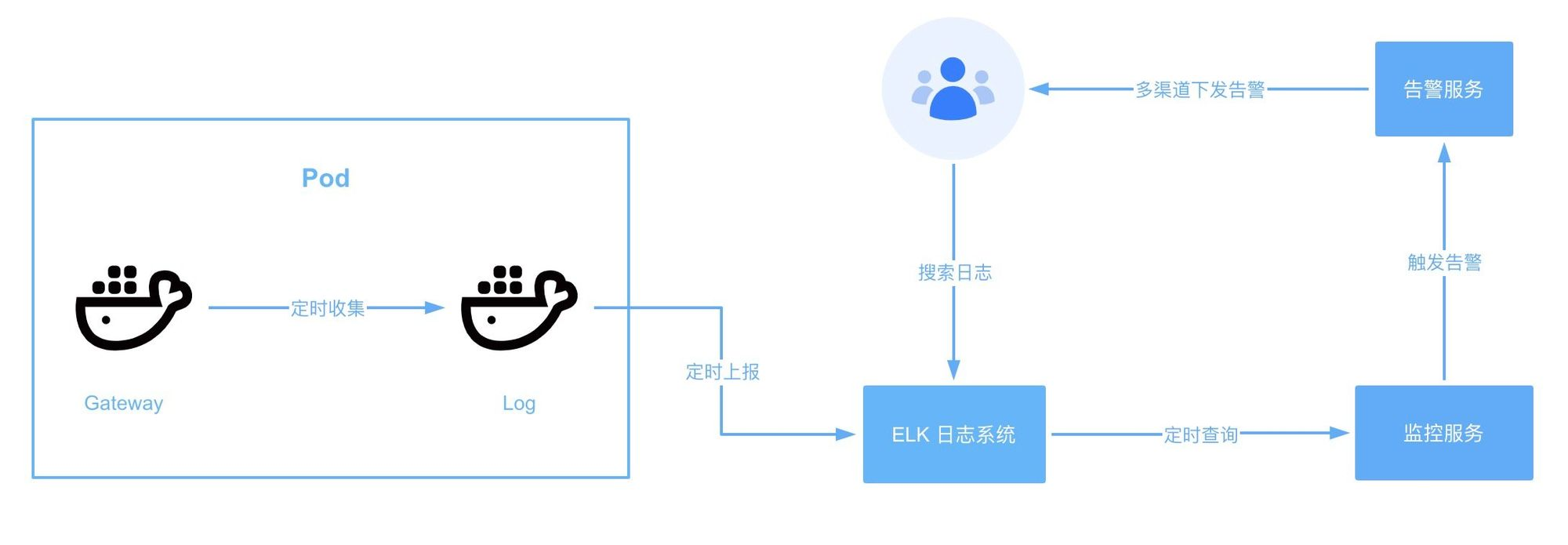
任务流程
- 解析告警规则
- 初始化时启动告警规则,向 elk 发起查询语句,目的是为了快速检测查询语句和告警规则是否有问题
- 根据 interval 字段开启定时查询器,定时从 elk 上搜索日志
- 查询的日志结果与 monit.thresholds 比较,不在范围内则发送告警
告警规则
1 | version: v2 |
version 指定解析器版本,向后兼容。
dataSource:指定 ELK 日志索引,否则会搜索所有索引的日志。
rules:每个 rule 都会启动一个轮询任务器。
rule.monit:query 是传给 ELK 的参数,aggs 是用来做聚合。
rule.period:分别统计[now, now - count] ~ [now, now - count*length]之间的满足条件的告警数量,都要满足 period 条件才不会发出告警。
更多规则
除了绝对值,告警还应该考虑到百分比或者相对值。
相对值可以用来告警性能:1-2 小时平均耗时(costTime)100ms,2-3 小时平均耗时(costTime)500ms。说明有问题,要发送告警。