一致哈希是一种特殊的哈希算法。在使用一致哈希算法后,哈希表槽位数(大小)的改变平均只需要对 K/n 个关键字重新映射,其中 K 是关键字的数量,n 是槽位数量。然而在传统的哈希表中,添加或删除一个槽位的几乎需要对所有关键字进行重新映射。
— 维基百科
应用场景
多用于分布式 Web 服务中。每个服务代表哈希环的一个节点,当此节点发生改变时候,例如挂掉,只有部分缓存会重新计算分布,而不是全部失效。
特性如下:
- 冗余少
- 负载均衡
- 过渡平滑
- 存储均衡
- 关键词单调
算法过程
假设我们目前有一个缓存集群,图中 node 代表集群节点。
下图就是哈希环,区间范围是 0 ~ 2^32,所有的值都会被 hash 过来(比如采用 hashcode 算法)。

读取缓存的步骤:
- 计算 node 哈希值,将其映射到 0 ~ 2^32 范围内
- 读取缓存时,计算缓存键对应的哈希值,映射到同一个圆上
- 顺时针查找圆,遇到的第一个 node
- 其上读取缓存,如果没有,那么更新缓存
更新缓存步骤:类似「读取缓存」
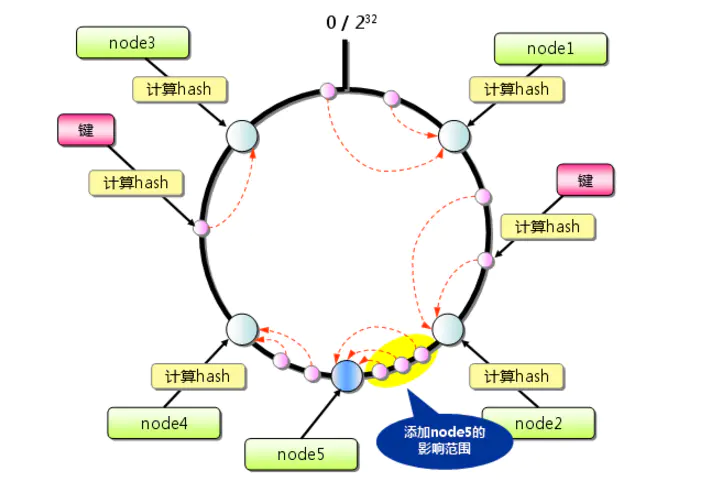
当 node 失效时,或者新加 node 时,只会有一部分缓存会变动,如上所示。
数据倾斜问题
如果服务节点太少,假设上图中,只有 node1 和 node3,那么大多数的缓存会落到 node1。
解决方法:每个 node,生成对应随机的 node 节点即可。
例如 node1 生成 node1#1、node1#2;node2 生成 node2#1、node2#2。
谷歌一致性哈希
jump consistent hash 是一种一致性哈希算法, 此算法零内存消耗,均匀分配,快速,并且只有 5 行代码。
1 | int32_t JumpConsistentHash(uint64_t key, int32_t num_buckets) { |
代码实现
在 nodejs 中,使用hashring.js。
1 | const HashRing = require('hashring'); |