应用场景
- 异步处理:将同步变成异步,提高主流程相应速度
- 系统解耦:各个系统通过 MQ 进行通信
- 数据同步:MQ 可以保证数据修改的有序性
- 流量削峰:系统瓶颈通常在 DB 上,可以考虑将数据写入 MQ 和 Cache,等流量过去,Worker 将数据刷到 DB 中
常见队列类型
缓冲队列:实现批量处理、异步处理和平滑处理。例如写日志,不用每次都写入磁盘,可以 10 次一起写入磁盘。
任务队列:存放异步任务。例如用户注册后,发送邮件、下发消息提醒、送优惠券等一系列动作,都可以放入任务队列。
消息队列:订阅发布模式,解耦各个系统。
请求队列:对用户请求排队,进行请求隔离、流量控制、分级处理等措施。
优先级队列:按照优先级执行 Worker。
混合队列:组装各种队列,例如对于一个系统的某个模块,其队列组成可以是请求队列 => 任务队列 => 失败任务队列。
举例:订单系统架构设计

有意思的点:
- (对应 step 2.1)对订单号 hash,将其“暂存”到缓冲数据表,通过 worker 同步到最终数据表。同步改成异步,降低数据表压力。
- (对应 step 2.3)如果上述的缓冲数据表异常,则“降级”写最终数据表。
- (对应 step 2.2)除了会将数据缓存到缓冲数据表,还会将数据“双写”到订单“缓存”。对外提供数据查询服务。
- (对应 step 5)为了保证缓存是最新的数据,订单中心的数据也会定时同步缓存。
举例:扣库存
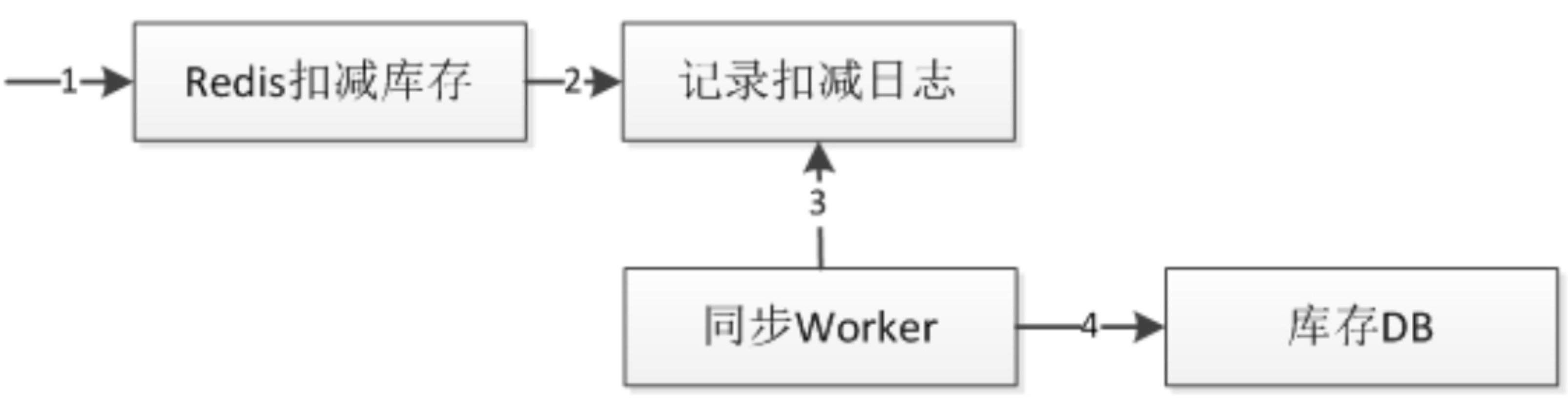
步骤:
- 数据从 DB 预加载到 redis 中
- 在 redis 上扣减库存
- 同步到 MQ 记录
- 脚本(Worker)定时消费 MQ 记录,进行一些业务校验、去重等逻辑,数据最终落盘到 DB
总结
上面两个例子,设计的核心点是:牺牲强一致性,但保证数据最终一致性。
并且队列适合频繁写的场景,技巧上就是通过缓存+队列的组合,来进行流量消峰。而读频繁的场景,技巧上就是通过多级缓存来抗。
参考
- 《亿级流量网站架构》